Today, data security and data privacy are hot topics for IT professionals worldwide. It’s no wonder, between persistent threats from cyberattacks such as malware and intrusions, accidental or intentional data loss, and data security regulations that impose stiff penalties on companies who ignore their data stewardship responsibilities.
But what exactly is the difference between data privacy and data security? In this article, we will discuss what those terms have in common and what sets them apart.
What is data privacy?
Data privacy legislation is primarily concerned with ensuring that individuals retain control over access to their personally identifiable information (PII), so it governs the procedures and policies for the collection, storage and use of PII. But data privacy also relates to preventing inappropriate access to other sensitive information, such as an organization’s trade secrets and internal processes.
What is a data privacy policy?
Ensuring data privacy requires more than a particular set of techniques or technologies. It also involves training every employee with access to sensitive data on the approved data protection processes. Just as an airplane pilot uses checklists to ensure that critical items are reviewed before and during flight, IT pros must also be able and willing to use data privacy policies and other resources to ensure the privacy of PII and other sensitive data.
Accordingly, organizations should implement a data privacy policy — a set of guidelines, processes and procedures that spell out in detail how sensitive data is collected, stored and used across all its systems. A solid data privacy policy can help ensure that all employees realize the importance of data privacy, understand how to help prevent improper exposure of data, and know how to deal with privacy issues and policy breaches.
What is data privacy legislation?
Data privacy laws include the Health Insurance Portability and Accountability Act (HIPAA), which protects healthcare-related personal information in the U.S., and the General Data Protection Regulation (GDPR), which imposes a broader set of privacy standards and regulatory compliance requirements on any company that stores or processes the PII of EU residents. Organizations should also keep an eye on regulations enacted by U.S states such as California, New York and Hawaii.
Mandates like these can impose stiff financial sanctions and even criminal charges for intentional or unintentional exposure of PII. Moreover, organizations often need to comply with more than one standard. Accordingly, it is vital to establish a comprehensive data privacy program.
What Is Data Security?
Data security is a broader concept than data privacy. It involves using physical and logical strategies to protect against data breaches, data loss and data corruption, whether caused by cyberattacks, errors, negligence or other factors.
Data security requires a holistic approach that addresses every network, application, device and data repository in the IT infrastructure. Measures for ensuring data security include:
- Resilient data storage technologies
- Encryption of data both at rest and in motion
- Physical and logical access controls that prevent unauthorized access
- Data masking
- Secure elimination of sensitive data that is no longer needed
Specific techniques for ensuring data security include multifactor authentication (MFA), multiple layers of access control at the network and application layer, and the detection and isolation of unauthorized devices as soon as they attach to a network. Regular backups and tested disaster recovery plans are also a big part of data security.
Data Security vs. Data Privacy
As we have seen, data privacy pertains to the governing of private data according to individuals’ wishes, while data security involves protecting data from threats. To illustrate this distinction, consider this example.
An organization implements strong data security measures, including ensuring that access to sensitive data is limited in accordance with the least privilege principle and that such data is encrypted and masked. But if it collects that data improperly — for example, by failing to get informed consent from the owner prior to data collection — it has failed to ensure data privacy.
Steps for Achieving Data Privacy
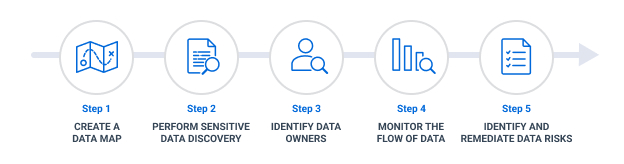
To help ensure data privacy, an organization can use an iterative process that includes these steps:
Note that this is not a once-and-done process. Rather, it needs to be repeated on a regular schedule, as well as when applications and data sets are being introduced or retired.
Step 1: Create a data map.
First, the organization needs to determine:
- Where data they have
- Who has access to each data set
- What access controls are in place and what gaps and inconsistencies exists
Step 2: Discover and classify sensitive data.
Next, the organization needs to categorize their data, so they know what types of data they have. This helps them prioritize securing repositories that store the most important or highly regulated data or otherwise pose the highest business risk.
Step 3: Identify data owners.
Data owners have the most knowledge about why data exists and who should have what access to it. They will be responsible for attesting to and governing access to the data they own.
Step 4: Monitor the flow of data.
Understanding how data is moving between repositories or geographic locations is vital to ensuring that sensitive data is always protected by appropriate security measures and access controls. Moreover, some national and local laws restrict data from moving outside of certain countries or areas. For instance, the GDPR dictates that data should not move outside of the EU without cause.
Step 5: Identify and remediate data risks.
By assessing the data collected in the previous steps, the organization should be able to determine its highest data risks and start devising and implementing strategies to ensure data privacy. Popular techniques and security products for spotting and fixing data risks include:
- Data discovery and classification
- Encryption
- Tokenization
- Masking
- Privileged access management (PAM)
- Data access governance (DAG)
- Data loss prevention (DLP)
How Netwrix Can Help with Data Security
Implementing strong data security practices is no longer just an admirable goal; it’s critical to avoiding steep compliance penalties, costly business disruptions, and lasting damage to the organization’s reputation and revenue.
Netwrix offers three solutions for maximizing data security:
- Data access governance software — Minimize your risk of a data breach by identifying your most critical data and ensuring that only the right accounts have the right access to that data.
- Information governance software — Reduce data risks during every stage of the information lifecycle, from ingestion or creation, through use and sharing, to eventual archival or disposal.
- Ransomware protection — Dramatically reduce your risk of ransomware infections by preventing malware from entering your systems in the first place, and promptly catching and stopping attacks before they can kidnap your data and ruin your business.
FAQ
What is the difference between data privacy and data security?
Data privacy involves controlling who sees personal information like bank account balances and credit card numbers, while data security protects data from unauthorized use, access, disclosure, modification, disruption or destruction.
Why are data privacy and data security so important?
Data privacy and data security are important because they prevent threat actors from accessing, corrupting, stealing and misusing confidential data. Organizations that don’t invest in privacy and data security solutions are at a high risk of having their data stolen and misused, which can lead to crimes like identity theft, reputational loss, business downtime, lawsuits and expensive fines.
How can an organization ensure the privacy and security of data?
Organizations can help ensure data privacy and data security by implementing cybersecurity solutions like Netwrix’s data access governance, information governance, and ransomware protection software. These platforms empower organizations to identify, prevent and mitigate cybersecurity attacks and help ensure that confidential data is protected at all times.


