
PART 2
Part 2 – Reachability-Distance & Local Reachability Density
In Part 1, I motivated the need for a density-based approach to outlier detection, and then I talked you through the first step of using the K-Distance as a framework for quantifying how “distant” a data point is from its neighbors. Today, I will walk you through the next two steps that will allow us to compute the local density of each data point.
Reachability-Distance
Now that we have the K-Distance for each point, we can construct the reachability distance. For two data points A and B, the Reachability-Distance of A and B is defined as the maximum of the K-distance of B and the distance between A and B. This is expressed mathematically as:
Reachability-Distance (A,B) = max{Distance(A,B), K-Distance(B)}
What does this mean? Well, let’s think about the reachability distance from the perspective of point B.
If a point A is one of point B’s k-nearest neighbors, then Distance(A,B) will be less than K-Distance(B), so Reachability-Distance(A,B) = K-Distance(B).
If a point A is not one of point B’s k-nearest neighbors, then Distance(A,B) is greater than K-Distance(B), so Reachability-Distance(A,B) = Distance(A,B).
In essence, we create a circle with radius K-Distance(B) around the point B. All points within the circle are “pushed” to the boundary of the circle. As a result, all of point B’s k-nearest neighbors are considered equidistant from B under the Reachability-Distance.
At this point, the reachability distance seems pointless. Why would we make all the nearest neighbors map to the same distance? In the introduction, I said Local Outlier Factor uses the density of a region to identify outliers. However, the true density of a region cannot be known in practice, so we have to estimate it somehow.
In the upcoming paragraph, I will show how the reachability distance is used as a heuristic to estimate the density of a region.
Local Reachability Density
Now, how do we estimate the size of our region? Well here’s where that confusing reachability-distance comes into play! For a point A and one of its neighbors B, the reachability distance shows us how B perceives the distance to A.
For a fun yet somewhat sad analogy, imagine if none of the people you considered to be your closest friends thought you to be one of their closest friends. Now you’re stuck in this awkward situation when you realize not one of your “best friends” thinks of you as a friend.
That’s essentially what happens to the outlier under the reachability distance. None of the outlier’s nearest neighbors consider the outlier to be one of their nearest neighbors. Returning to our example, I have once again shown the K-distance around our outlier, but this time I have also one of its nearest neighbors.
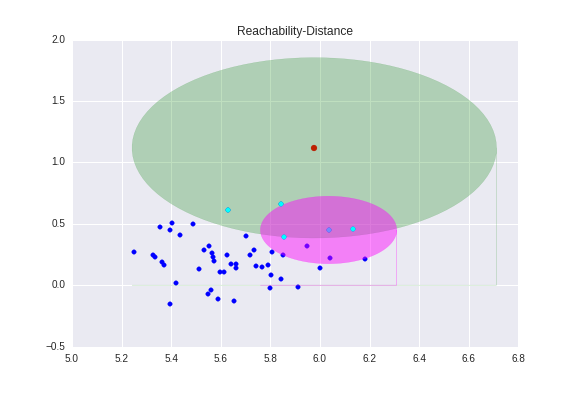
Notice how the outlier is not contained in the K-neighborhood of its neighbor. This means that while the outlier considers that point to be one of its nearest neighbors, the neighbor does not think the same of the outlier.
Formally, the Local Reachability Density for a point A is computed as:
LRD(A) = Average Reachability-Distance of A’s neighbors
You may be wondering why it’s necessary to take the inverse of the average reachability distances to compute the LRD. Returning back to our Density = Mass/Volume metaphor, the average reachability-distance represents the “volume” of our region localized about point A, but we need volume in the denominator in order to compute the density. Hence, we take the inverse in order to have our “volume” in the denominator. This explanation is a bit of an oversimplification, but it provides the necessary intuition for the inverse in our calculation.
As I stated in the introduction, we expect our outliers to be in less dense (sparser) regions compared to normal points. Therefore, our outliers should have lower local reachability densities, showing that the density around our outlier is lower than those of the other points in the dataset.
The Local Reachability Density provides us with an estimate of the “statistical density” for each point. In Part 3, I will use the Local Reachability Densities to identify points that are statistically more likely to be anomalies, so stay tuned for tomorrow’s post!
Real-World Example
Now, let’s return to our IT Admin checking out credentials from her PIM. Of course, when she checks out the privileged credentials, she’d not doing the exact same thing every time, but her individual actions are very similar. Maybe one time she accidentally mistypes the password once before logging into the proper machine to make a change. Maybe it was a different machine that was having issues than last time. There’s no question those behaviors have differences to previous episodes. The important factors, however, are similar: she still went to just one machine, made one change, then released the privileged credentials and moved on to something else.
In this example, relying on just the K-distance analysis may produce a false positive, when in fact, the deviation from the norm was, in reality, insignificant. The reachability distance and local probability density is a way to abstract away minor differences and find larger trends in behavior, effectively adding another level of complexity and credibility to the analysis.
Don’t miss a post! Subscribe to The Insider Threat Security Blog here:

Manojit Nandi is data scientist at STEALTHbits Technologies. He holds a Bachelor of Science in Decision Sciences, focused on machine learning and mathematical algorithms, from Carnegie Mellon University. He has given talks on machine learning and data science at tech conferences, such as SIGKDD and PyData.
Related Posts
- Sensitive Data Discovery for Compliance
- Using The Azure Information Protection (AIP) Scanner to Discover Sensitive Data
- Advanced Data Security Features for Azure SQL- Part 1: Data Discovery & Classification
- How to Protect Office 365 by Classifying Your Data with Microsoft’s AIP Labels
- 2019 Verizon DBIR Key Findings
- 5 Cybersecurity Trends for 2019
- EU GDPR: Paving the Way for New Privacy Laws?
- Announcing Stealthbits Activity Monitor 3.0 & StealthINTERCEPT 5.1
- Key Take Aways from the Ponemon 2018 Cost of Insider Threats Report
- Where Real Organizations Are with EU GDPR 10 Days from Launch
Thank you so much for this wonderful explanation.
For so long I was wondering why do we even have to consider the actual distance between two points in reachability distance.
I was not considering that we have to think from perspective of neighbours.